
Prepare-se: a verdadeira revolução dos dados ainda nem começou
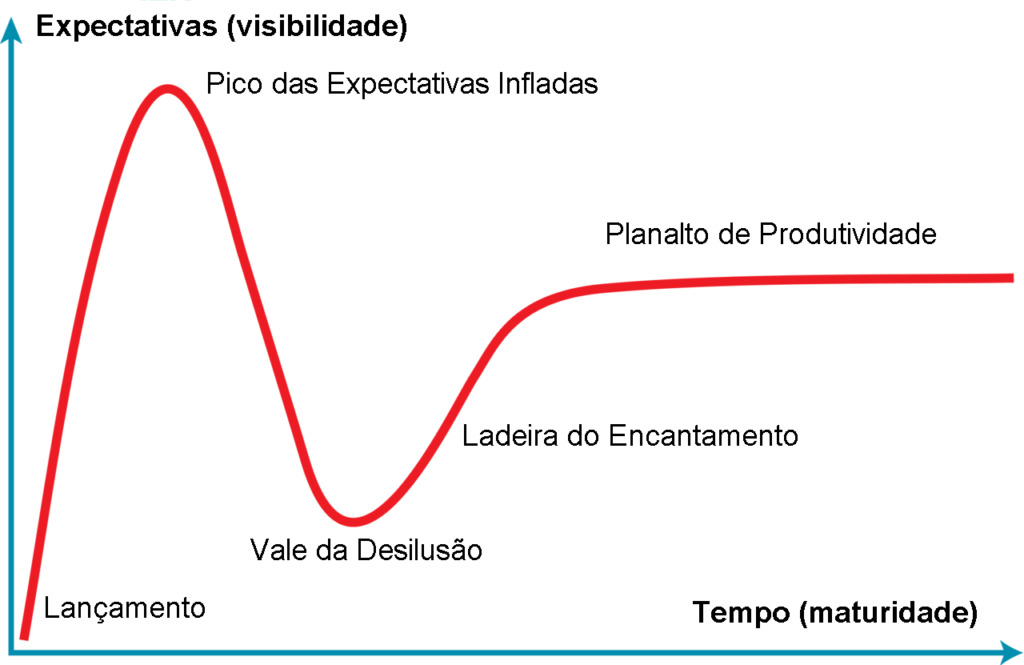
O Hype Cycle da Gartner é uma ferramenta útil para entender em que estágio uma tecnologia emergente está em sua trajetória rumo à adoção em larga escala. Ele acompanha a percepção do público desde o “pico das expectativas infladas”, passando pelo “vale da desilusão”, subindo a “ladeira do esclarecimento” até atingir o “platô da produtividade”.
Em 2015, no entanto, a empresa retirou o big data do estudo. Segundo a analista Betsy Burton, ele deixou de ser uma “tecnologia emergente e passou a fazer parte do dia a dia”.
Ela tem razão. Com o tempo, ficou claro como as empresas rapidamente perceberam o valor dos dados e aprenderam a usá-los a seu favor. O big data deixou de ser uma novidade e se tornou uma necessidade – e isso aconteceu em ritmo impressionante.
Mas, em certa medida, discordo da avaliação da Gartner. Sim, o uso do big data se espalhou. Mas explorá-lo de forma eficaz é outra história.
A maioria das empresas realmente conta com as ferramentas e a infraestrutura necessárias para extrair o máximo dos dados que possui? Na minha opinião, não. É por isso que acredito que a verdadeira revolução dos dados ainda não aconteceu. Mas ela está chegando.
Um dos motivos pelos quais o big data é visto como uma tecnologia já consolidada – e até comum – é a confusão entre avanço de software e maturidade do ecossistema como um todo. A realidade é bem mais complexa.
É inegável que os softwares evoluíram bastante. Hoje, temos plataformas robustas para gerenciar, consultar e analisar grandes volumes de dados. Muitas empresas já contam com bons conjuntos de ferramentas. Mas esses softwares precisam de hardware para funcionar. E é aí que mora o problema.
Hoje, a maioria ainda roda em CPUs – os mesmos processadores usados em tarefas comuns de TI. Eles são caros, consomem muita energia e não são ideais para tarefas que exigem processamento paralelo.
Quando uma consulta precisa ser executada a partir de terabytes – ou mesmo petabytes – de dados, os engenheiros costumam dividir o trabalho em várias partes menores e processá-las em sequência. Esse método é lento, ineficiente e, no fim, exige mais poder de computação do que se fosse executado de uma vez só.
Mesmo com altas velocidades de clock, as CPUs não têm núcleos suficientes para processar consultas complexas em grande escala. Por isso, o hardware tem sido o grande limitador do potencial do big data. Mas isso está começando a mudar com o avanço da computação acelerada.
RESOLVENDO O GARGALO
Computação acelerada é o uso de hardwares especializados que oferecem desempenho superior ao das CPUs. Entre eles estão os FPGAs (circuitos programáveis) e os ASICs (circuitos criados para tarefas específicas).
Mas, quando falamos de big data, os grandes protagonistas são as GPUs – processadores gráficos com milhares de núcleos, perfeitos para tarefas que se beneficiam de processamento paralelo. Elas conseguem acelerar de forma significativa operações em grande escala.
Curiosamente, a computação com GPUs e o big data surgiram quase ao mesmo tempo. Em 2006, a Nvidia lançou o CUDA (Compute Unified Device Architecture, ou Arquitetura de Dispositivos Unificados de Computação), que tornou possível utilizar GPUs para computação geral. Dois anos antes, o Google já havia publicado um artigo sobre MapReduce, que se tornaria a base do processamento moderno de grandes volumes de dados.
Com GPUs mais acessíveis e ferramentas maduras, as limitações de hardware estão sendo superadas.
Apesar desse desenvolvimento paralelo, as GPUs ainda não se tornaram a norma nas infraestruturas de dados corporativas. Isso se deve a vários fatores. Por muito tempo, o acesso a GPUs em nuvem era bastante limitado. Quando comecei a desenvolver softwares com aceleração por GPU, a SoftLayer – hoje parte da IBM Cloud – era praticamente a única opção disponível.
Também havia uma questão de percepção: muita gente achava que desenvolver com GPU era algo caro e complexo demais, especialmente para aplicações de negócios. E, por muito tempo, quase não existiam ferramentas que facilitassem esse processo. Felizmente, isso mudou.
Hoje, existe um ecossistema robusto de ferramentas que dão suporte à computação com GPU. As ferramentas baseadas em CUDA amadureceram ao longo de quase duas décadas. E já é possível alugar um GPU de última geração, como o Nvidia A100, por cerca de US$ 1 por hora.
Com acesso mais barato e uma base tecnológica mais madura, temos finalmente os ingredientes certos para o próximo passo.
A VERDADEIRA REVOLUÇÃO DO BIG DATA
O que vem por aí será transformador. Até agora, o maior entrave era o hardware. Agora, com GPUs mais acessíveis e ferramentas maduras, essas limitações estão sendo superadas.
O impacto vai variar de empresa para empresa. Mas, no geral, as organizações poderão realizar operações complexas com grandes volumes de dados sem se preocupar com o tempo de execução ou com os custos de processamento.
Com insights mais rápidos e baratos, os negócios poderão tomar decisões melhores e responder com mais agilidade. O foco deixará de ser a quantidade de dados coletados e passará a ser a rapidez com que esses dados podem ser utilizados.
A Gartner retirou o big data do Hype Cycle porque ele deixou de parecer algo revolucionário. Mas a computação acelerada está prestes a torná-lo revolucionário novamente.

